RCVM: Robot Communication Via Motion
Relevant Publications:
ICRA-19 RSS-22 IROS-22 THRI-21Many AUVs use small digital displays to convey information to divers working collaboratively with them. However, these displays can be hard to read. To allow AUVs to communicate more freely, regardless of the relative position of divers, I created Robot Communication Via Motion (RCVM) for AUVs. The gestures of this communication method are called kinemes, and are shown below.

In an initial study, RCVM outperformed a light-based baseline method at all levels of education (None, names of kinemes, full training).
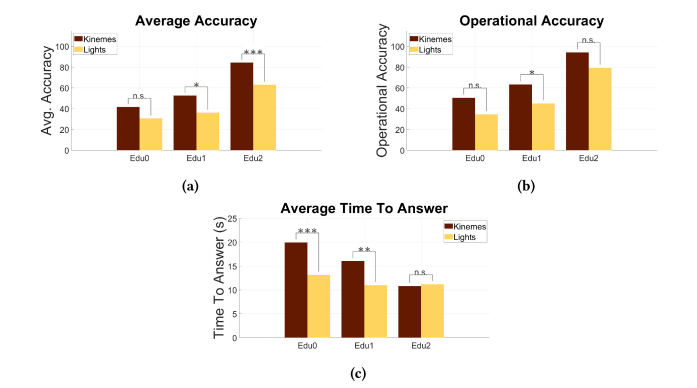
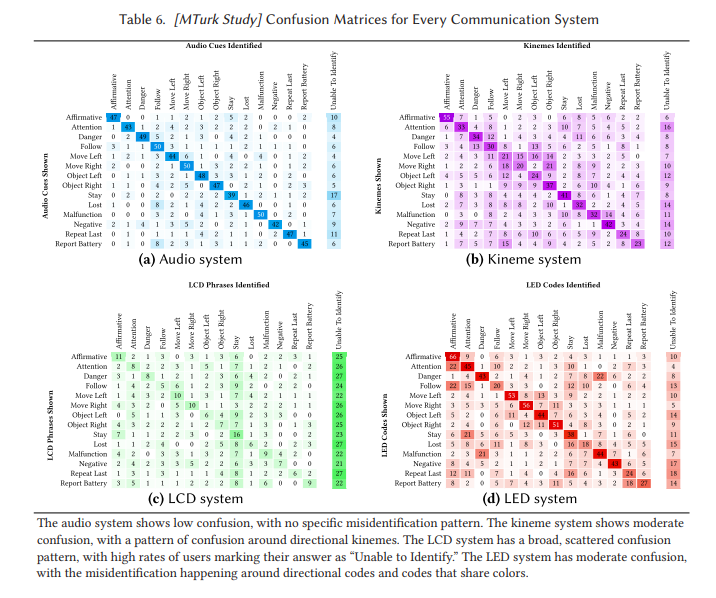
Following this, we compared RCVM with a light-based communication method, a sound-based method, and a digital display. We also compared RCVM’s effectiveness at different viewpoints and kineme content. We discovered that RCVM is more resistant to change in viewpoint than other methods.
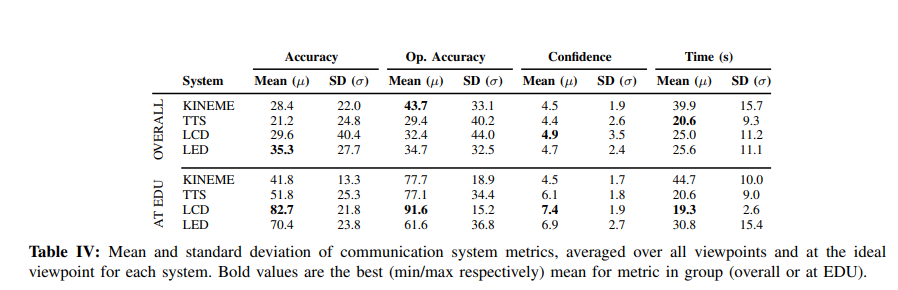
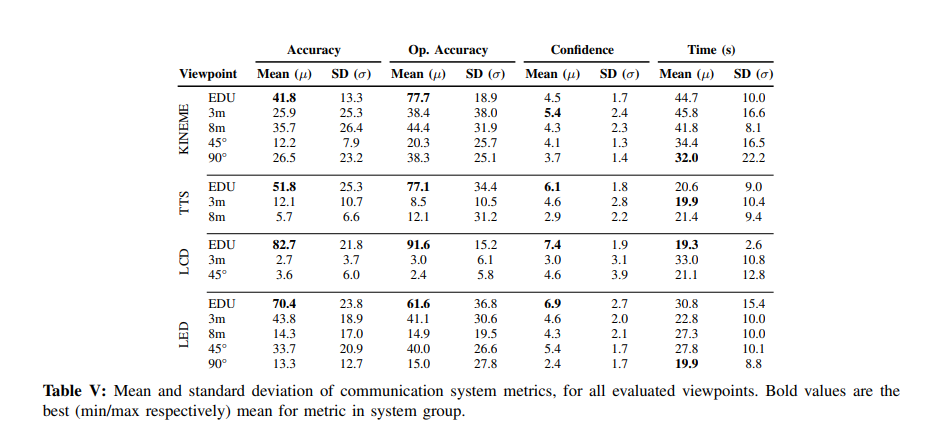
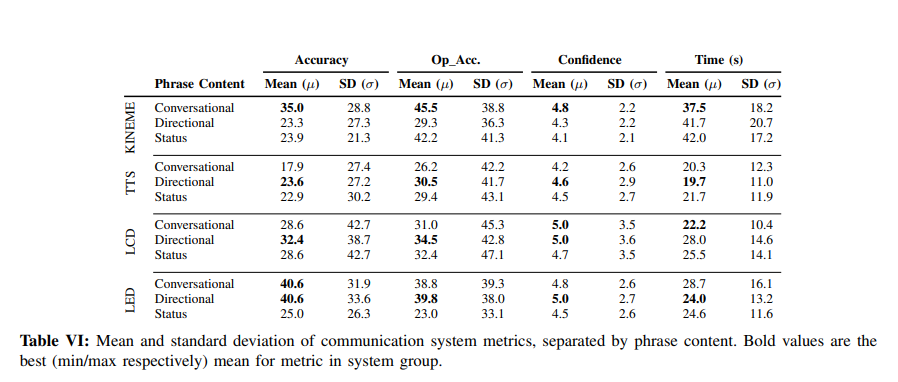
We also implemented all of these systems for a terrestrial robot and an aerial robot. The following confusion matrices include all of these systems.
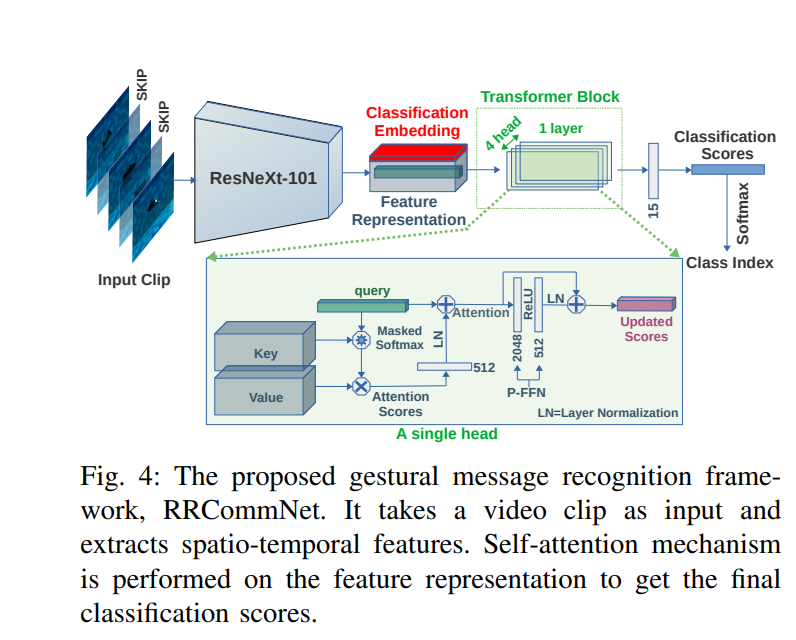
Sadman Sakib Enan has built on my work by developing a deep learning architecture which can recognize kinemes. I helped in this work by evaluating human transcription of robot-to-robot kineme conversations, to ensure that humans could also understand robot conversations, making the language universal.